In the quest for more reliable AI reasoning, “Single Shot” prompting often falls short. Hallucinations creep in, and biases go unchecked. To solve this, we turned to Multi-Agent Systems (MAS).
Our goal was simple: reduce hallucinations and enhance realism by making agents check each other’s work. Our journey evolved through three distinct architectural phases over the last year.
Phase 1: The “Scripted Play” (May 2025)
Our first attempt was a Workflow-based system. We read numerous papers and implemented a standard structure: a Moderator, a Reviewer, and Red/Blue teams.
- Architecture: Rigid, linear workflow.
- Mechanism: We manually coded the sequence:
Blue Argue -> Red Critique -> Moderator Summary. - The Problem: It was “Form over Function.” The agents had Zero Agency. They couldn’t search the web, read files, or verify facts. They were just LLMs role-playing within a fixed prompt template. The debate looked structured, but the content was often hollow because the agents lacked the tools to ground their arguments in reality.
Phase 2: The “Relay Station” (August 2025)
In August, we rebuilt the system in our experimental labs project, basing it on a flow-based architecture (referencing ByteDance’s Deer Flow).
- The Upgrade: Agents gained Tool Use (Web Search) and Context Isolation.
- Mechanism: The Moderator acted as a Hub. It would take a topic, call the Blue Agent, get the result, pass it to the Red Agent, and so on.
- The Limitation: While agents could now search for external info, they were still “deaf.” They didn’t truly “hear” each other. The Moderator was just relaying summaries. There was no “Group Chat” dynamic. The agents were isolated workers, not collaborators in a shared room.
Phase 3: The “Autonomous Council” (Dec 2025 - Jan 2026)
With the release of our DeepAgents V3 engine, we reached our current architecture. The system now supports three distinct reasoning frameworks, all powered by the same underlying A2A (Agent-to-Agent) engine:
1. Red/Blue Team (Adversarial Analysis)
Used for critical decision making.
- Red Team: Attacks the plan, finds risks.
- Blue Team: Defends the plan, provides evidence.
- Outcome: A stress-tested strategy with exposed blind spots.
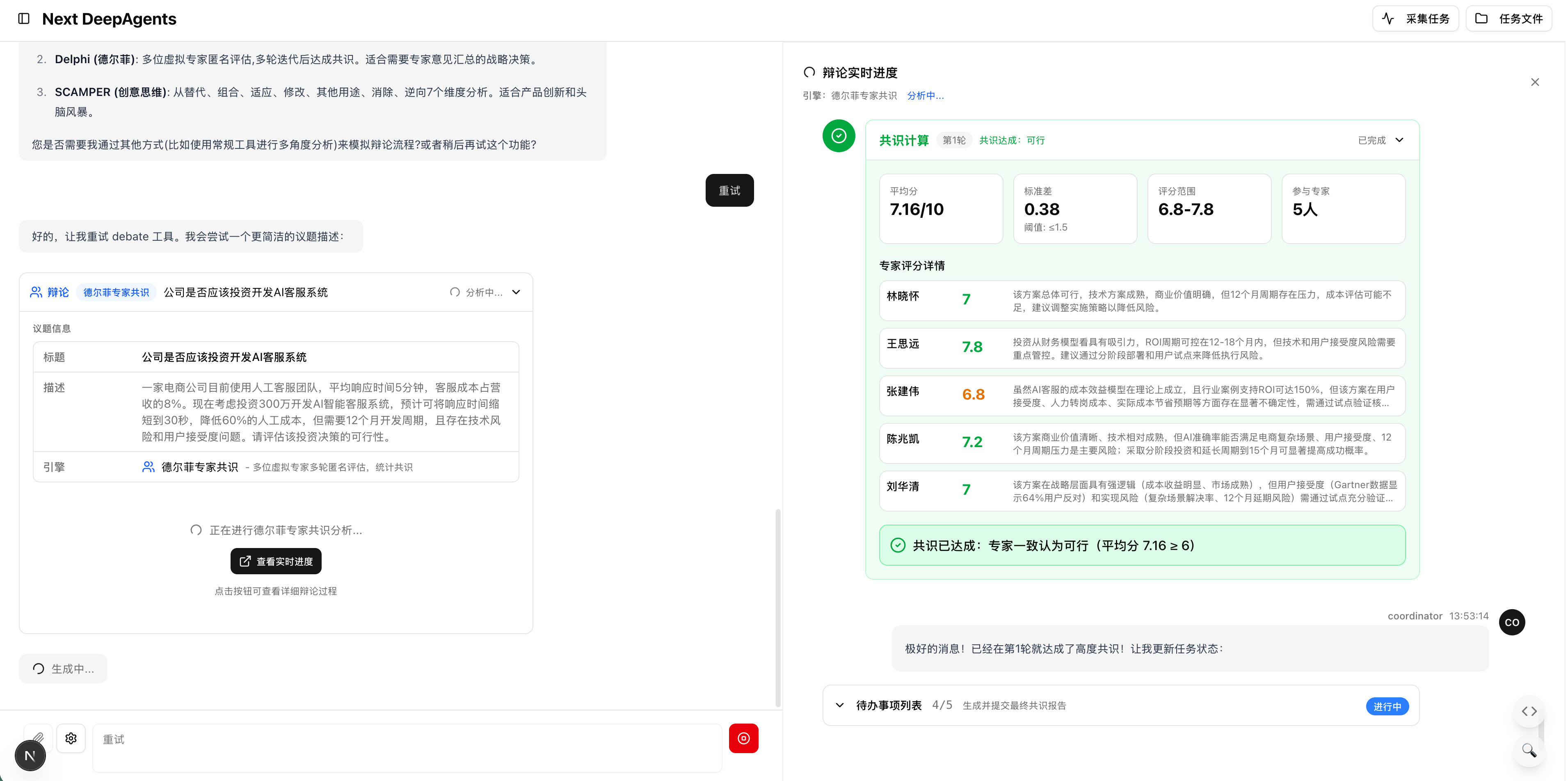
2. The Delphi Method (Expert Consensus)
Used for forecasting and complex estimation.
- Experts: Multiple anonymous agents provide independent estimates.
- Facilitator: Summarizes the range of opinions and feeds them back.
- Outcome: Convergence towards a highly accurate consensus.
3. SCAMPER (Creative Ideation)
Used for brainstorming and product innovation.
- Roles: Substitute, Combine, Adapt, Modify, Put to another use, Eliminate, Reverse.
- Outcome: A massive expansion of creative possibilities.
Future Roadmap: Six Thinking Hats
We are also exploring Edward de Bono’s “Six Thinking Hats” to further structure the emotional and logical dimensions of agent reasoning.
The Core Insight: The “A2A” Philosophy
The biggest technical takeaway from this evolution is what we call the A2A (Agent-to-Agent) Philosophy, even without a formal protocol.
In V3, we achieved a delicate balance:
- Context Isolation: Each agent runs in its own memory space.
- Collaboration via Tools: The “Debate” is essentially one Master Agent calling other Agents as Tools.
By wrapping Agents as Tools, we achieve Context Isolation (clean reasoning) with Collaborative Output (shared goals). This “Implicit A2A” pattern has become the backbone of our system stability.